Background
The problem



The user
While 33% of enabled users have interacted with the tab, only 0.5% have contributed to it by posting a message.
This is because those engaging with the community are power users who are comfortable posting and have a wealth of information to share, while the majority are lurkers, watching posts and occasionally contributing. The average user is someone like Anna, who has some information to share but is a bit wary.

The proposed journey
We can't solve financial crime making an impact globally if we only look in isolation at the little piece we are privy to. Allowing for more crowdsourced information and human input allows the model to be educated faster, as well as enhance customer loyalty and retention through experiences that explicitly highlight Chainalysis’ network effect.
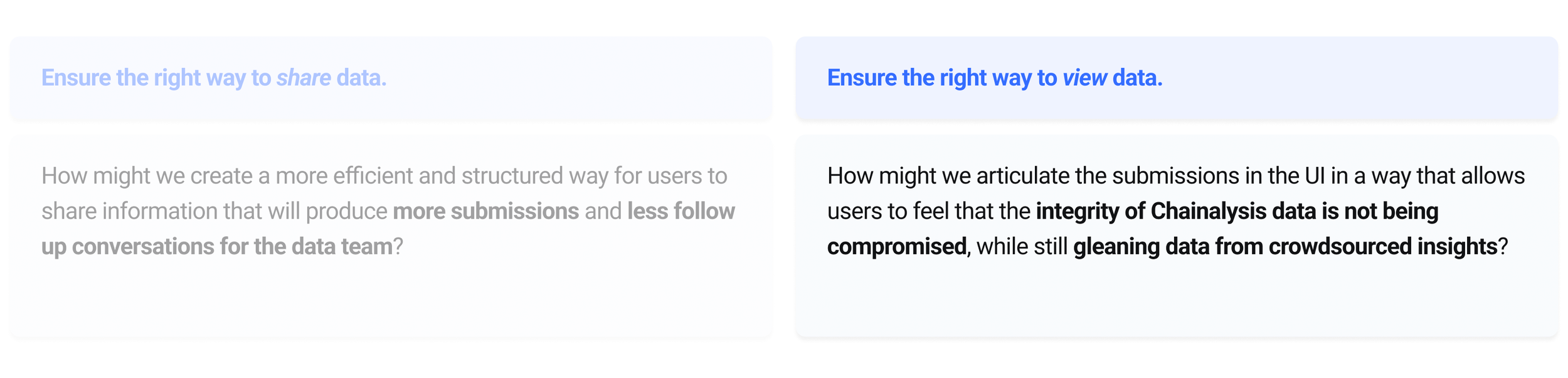
How do we walk the line between actual validity of information (making sure we get the right message of what an ID is) and the perceived validity or confidence in that information (making sure its perceived properly)?

Success metrics
# of clusters attributed based on crowdsourced information.
# of views of Community tab for clusters which have crowdsourced information.
Hypothesis
If Chainalysis creates a more efficient and structured way for users to both share and view potential identifications via crowdsourced data, user’s will be able to get more valuable data to make compliance and investigation decisions.

Crafting the beta

Efficiency- how do we want our users to interact with data entry?
How do we ensure that the power users are able to complete the task with little friction, while the average user can receive the tools they need?

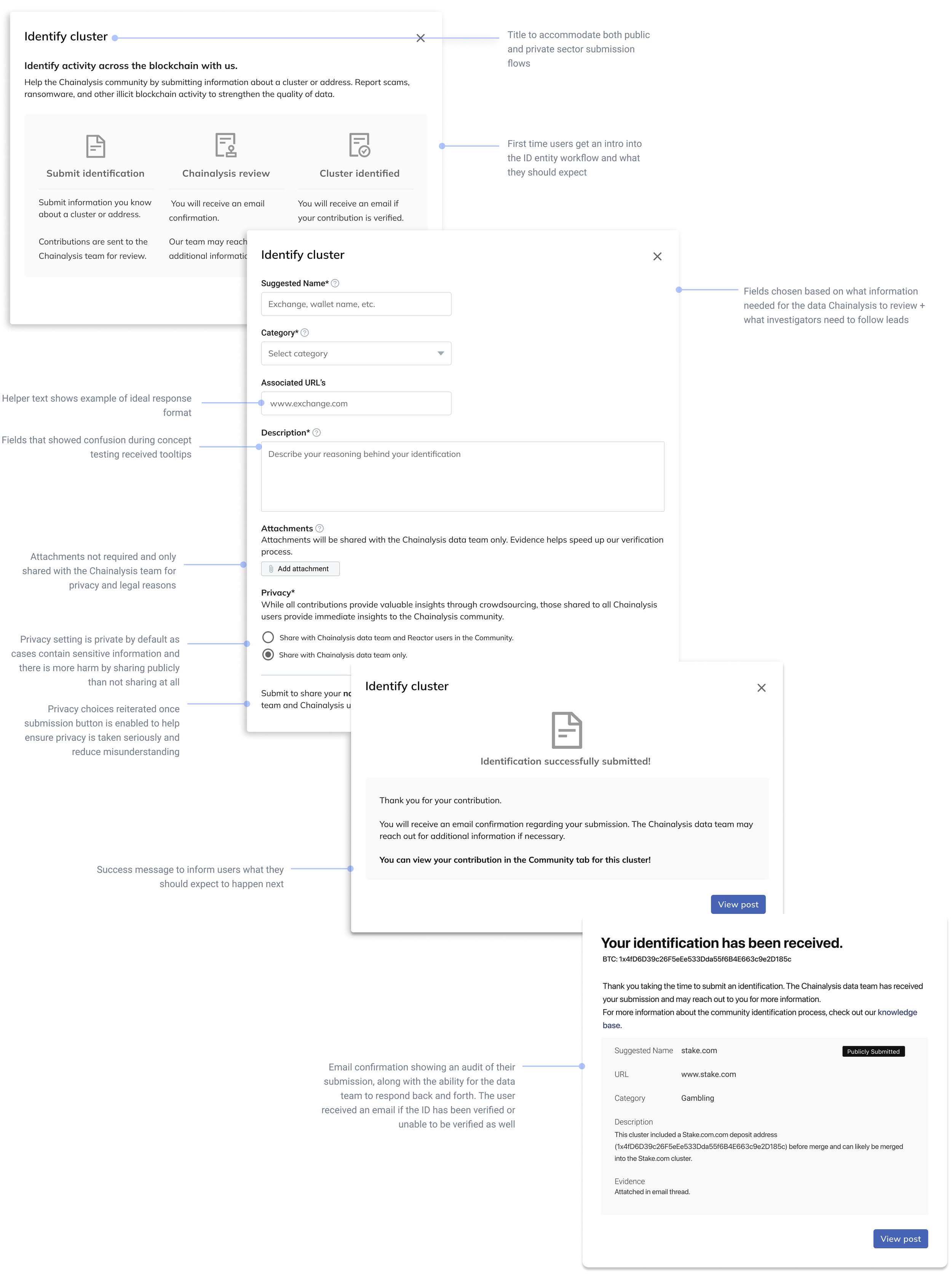
Form fields for every user
The design chosen was the modal approach, with an additional screen for first time users. The modal allows for flexibility of entry points and a growing scope. While entering directly from the community message may be the path of least friction for our power users, it does not scale well as the data entry becomes more complex, new entry points and use cases appear, and new user groups (public sector) are accounted for.
The final form for data input was gathered from looking at trends in previous submissions to see what users can provide, working with our data team to see what fields they would require to verify the submission, and what fields users would want to see to make an educated guess as to whether they should consider it for a lead.
Structure- how do we want users to Interpret crowdsourced data?
User research showed that quality of data is a huge concern if crowdsourced information becomes available to the wider Chainalysis community. Users implicitly trust that the data that Chainalysis verifies is held to a higher standard than community-submitted information.
How do we communicate that this information has more structure and conviction than a conversational community post, but also is not fully verified by Chainalysis?

Information hierarchy
How do we consider the hierarchy of information? Is the primary information to ingest the name of the submission or the information type? Do users know that these posts are differentiated from traditional community posts? The initial version contained the information type as the prominent piece of information as this was a new workflow. After some time for users to adjust to this type of content and some concept testing, we moved to adding the title as the main focal point.

Final post UI
The final version of the community post does not use color to visually distinguish that the identification is different than the typical community post, it uses a system label. While the colored banner stood out visually, it did not allow for a potential increase of scope of post types in the future, and the system labels act as both a recognition of the type of post, as well as the status.

Beta findings
Within the first few months, we were receiving 5x more submissions that the previous methods and the adoption was well received. However, there was one use case that we did not account for. We needed to learn more about this unintended use case and find a path forward.
The problem

As an investigator…
I have information on a specific address, but I can only submit information about a cluster to the Chainalysis team.
I am searching the address of a coin that Chainalysis does not yet support, and there is no information on it because the data ops process has not started.
I want to be able to identify and view the activity of an address in the context of the service it is nested within, without having to pull it out into a separate cluster entirely.
Initial (wrong) understanding
The concept of “nested services” was a bit nebulous at Chainalysis. We initially were under the impression that we would need to differentiate between a cluster, private wallet (address), and nested service (address) identification. This led to explorations around how they were differentiated and how that could be reflected in the product.

The solution: Address-level identifications
After working with the data team, we uncovered that nested services should more broadly be referred to as a nested entity because it could be a service (e.g. a Gambling site using a Merchant Service to process payments) OR a non-service entity (e.g. the proceeds of stolen funds to the thief’s account at an exchange).
A nested entity would never be a private wallet because the nested entity is using the parent entity to custody the funds. That means the nested entity does not hold the private keys. If it is a private wallet then the identification should be cluster level because it is a single private entity with no nested activity.
TLDR- We initially thought we needed to differentiate between identifying a cluster, nested address, and independent address. However, an address that hasn’t been identified yet is technically it’s own cluster, and everything else is just nested within a cluster. This realization led to the formation of one single address level identification, that either gets nested or is it’s own cluster.
Final understanding
Address-level identifications allow us to highlight the concerning activity nested within entities, but not label the entire cluster as a risky entity. Additionally, they are valuable for exposing addresses associated with risky activity nested within larger services.

Mapping the new flow

Production launch
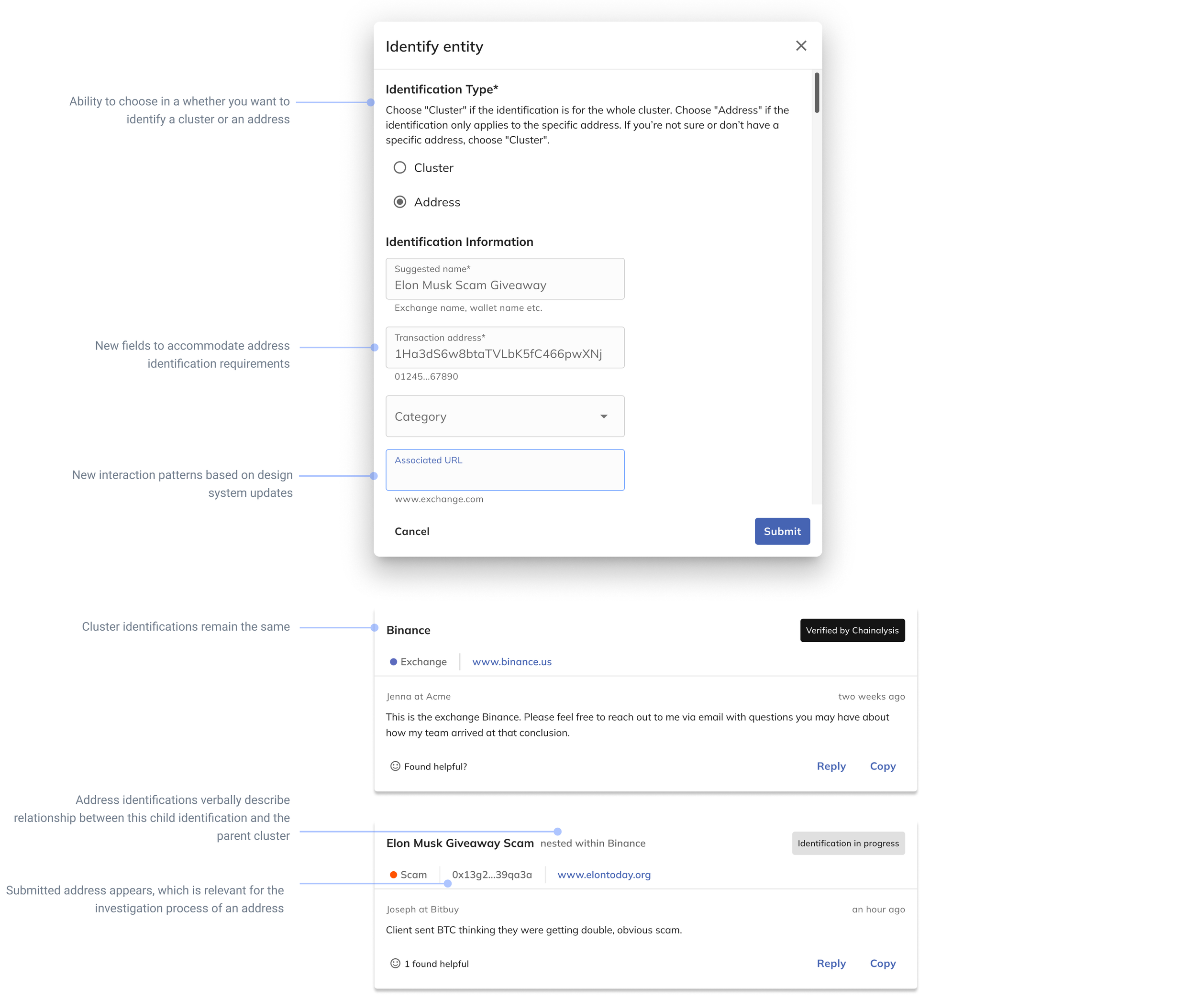
In the final phase of the workflow, it maintains the same general flow, with the title change from “identify cluster” to “identify entity” in order to showcase breadth beyond a cluster. The user can now select if they are identifying a cluster or an address. There is an additional field for inputting a tx address if address is selected.
As for the posts, they also maintain the same structure, however, nested entities are represented by simply stating [Suggested name] “nested within” [Cluster ID]. We experimented with adding more tags as a means of categorizing this information, but ultimately it was an instance where plain speak text best conveyed the message.